Khabar Scraper - News Data Extraction
Project Overview
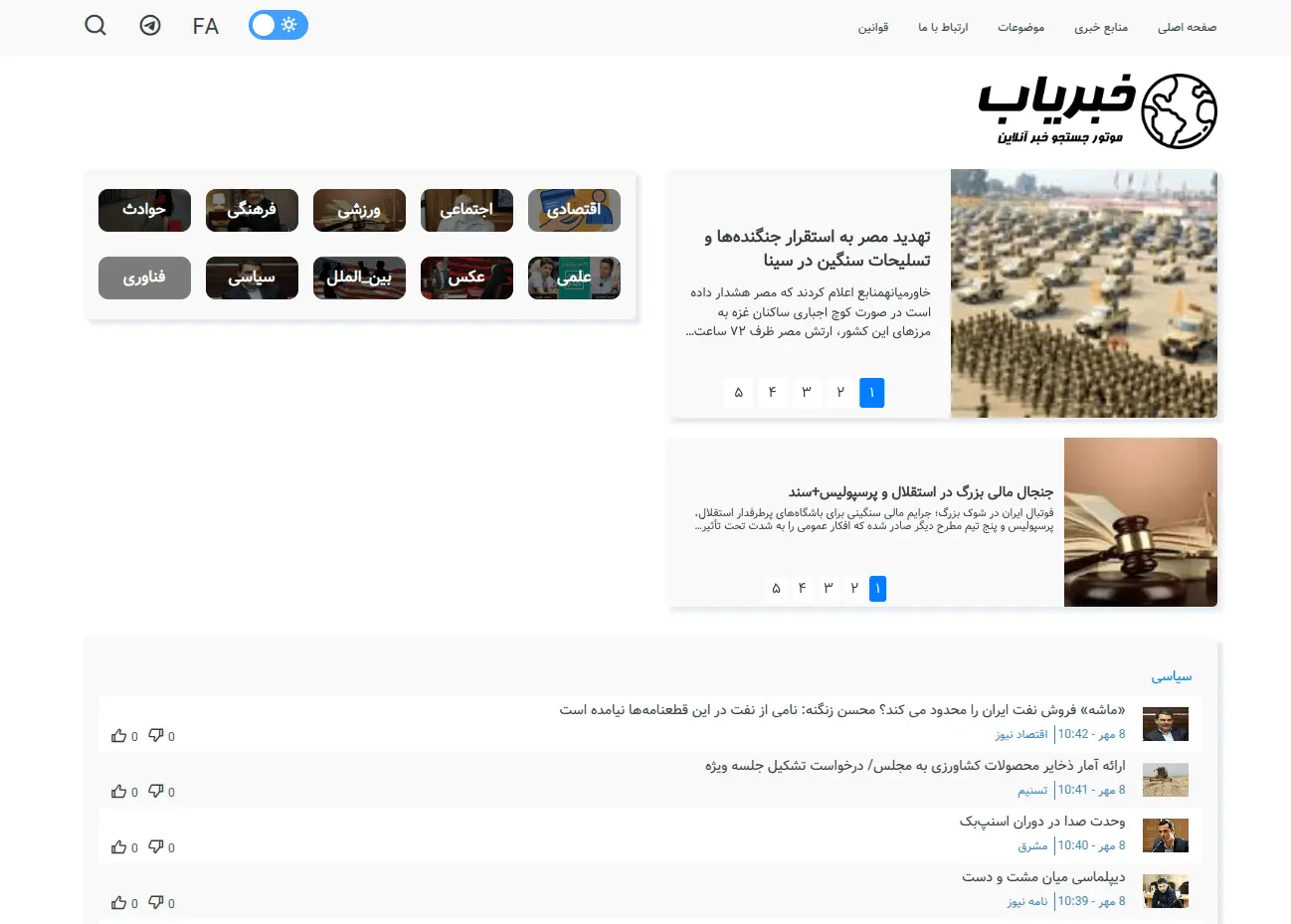
Khabar Scraper is an intelligent web scraping system designed to extract, process, and analyze news articles from Persian news websites. The project automates the collection of news data, enabling efficient monitoring of news sources and providing structured data for further analysis.
Developed for Hunam Computer, this tool streamlines news aggregation workflows and supports content analysis, trend detection, and media monitoring applications. It handles various website structures and implements robust parsing techniques to ensure data quality and consistency.
Key Features
- Automated news article extraction from multiple sources
- Intelligent content parsing and cleaning
- Support for Persian language text processing
- Structured data output in various formats (JSON, CSV)
- Duplicate detection and filtering
- Scheduled scraping with configurable intervals
- Error handling and retry mechanisms
Technology Stack
Python
Core language for scraping logic, data processing, and automation
BeautifulSoup & Scrapy
Web scraping frameworks for parsing HTML and extracting content
NLP Libraries
Natural language processing tools for Persian text analysis and cleaning
Results & Impact
Khabar Scraper has successfully automated the news collection process, reducing manual effort and enabling real-time monitoring of news sources. The system processes thousands of articles efficiently, providing clean, structured data for downstream applications such as sentiment analysis, trend detection, and media research.
Future Enhancements
- AI-powered content categorization
- Sentiment analysis integration
- Multi-language support expansion
- Real-time alert system for breaking news
- Advanced data visualization dashboard
Project Gallery