Deep Q-Network (DQN) Reinforcement Learning
Project Overview
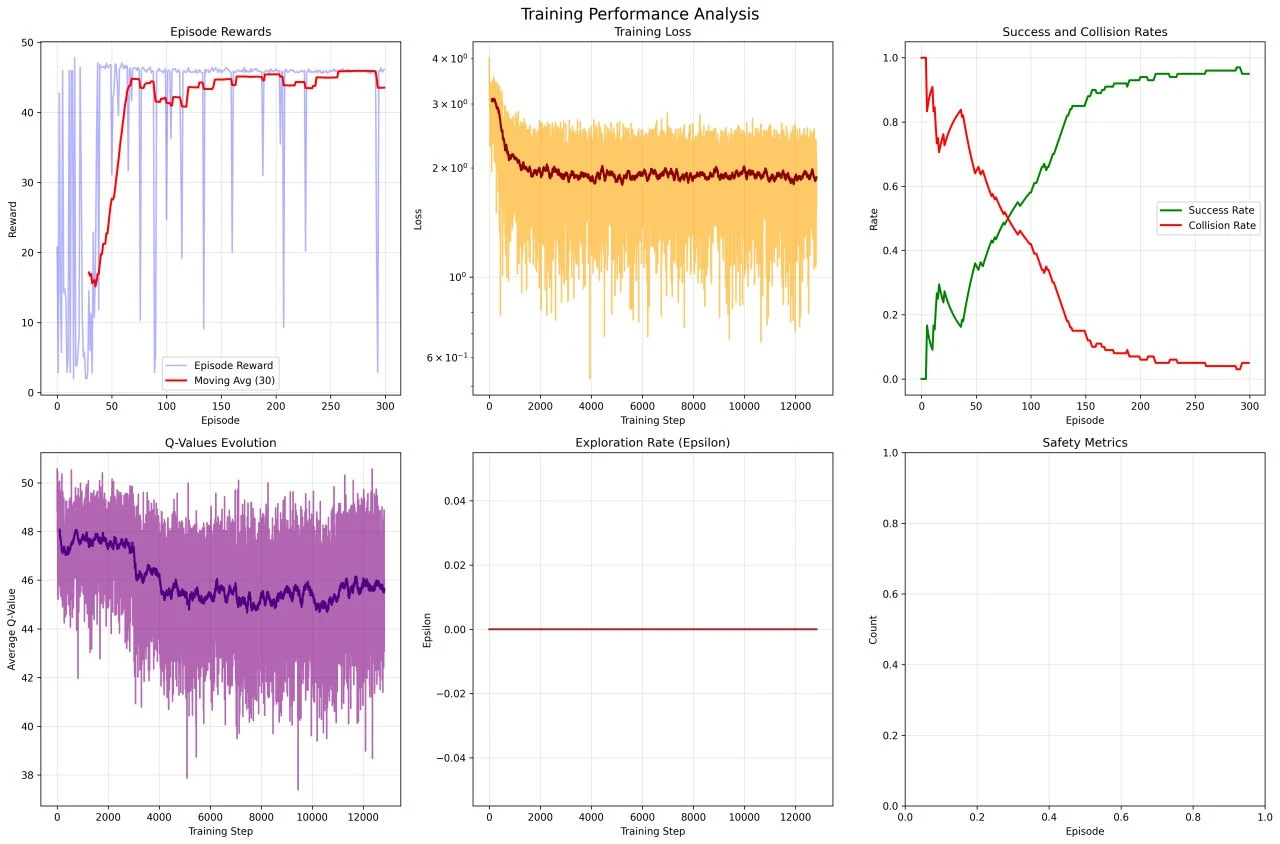
The DQN Project implements Deep Q-Network algorithms for reinforcement learning tasks. This project explores the application of deep learning to Q-learning, enabling agents to learn optimal policies in complex environments through trial and error. The implementation includes various enhancements to the base DQN algorithm for improved stability and performance.
The project demonstrates the power of combining deep neural networks with reinforcement learning, showcasing how agents can learn to make intelligent decisions in dynamic environments. Applications include game playing, robotic control, and autonomous decision-making systems.
Key Features
- Implementation of classic DQN algorithm
- Experience replay mechanism for stable learning
- Target network for improved convergence
- Support for various OpenAI Gym environments
- Double DQN and Dueling DQN variants
- Visualization of learning progress and metrics
- Configurable hyperparameters and network architectures
Technology Stack
Python
Core programming language for implementing RL algorithms and training loops
TensorFlow / PyTorch
Deep learning frameworks for building and training neural network models
OpenAI Gym
Standardized environment interface for testing and benchmarking RL algorithms
Results & Impact
The DQN implementation successfully learns optimal policies across multiple environments, demonstrating human-level or superhuman performance on various tasks. The project serves as a foundation for understanding deep reinforcement learning and has been used to explore advanced RL techniques and their applications in real-world scenarios.
Future Enhancements
- Implementation of Rainbow DQN with all improvements
- Multi-agent reinforcement learning scenarios
- Transfer learning capabilities across environments
- Real-world robotic control applications
- Distributed training for faster learning
Project Gallery